1. Functional Programming in Scala, EPFL
 I completed the Functional Programming in Scala online course from EPFL with distinction, 100% (top 7% of class). I enjoyed the challenging exercises and would be very interested in a follow up course, as proposed by Martin Odersky.
I completed the Functional Programming in Scala online course from EPFL with distinction, 100% (top 7% of class). I enjoyed the challenging exercises and would be very interested in a follow up course, as proposed by Martin Odersky.
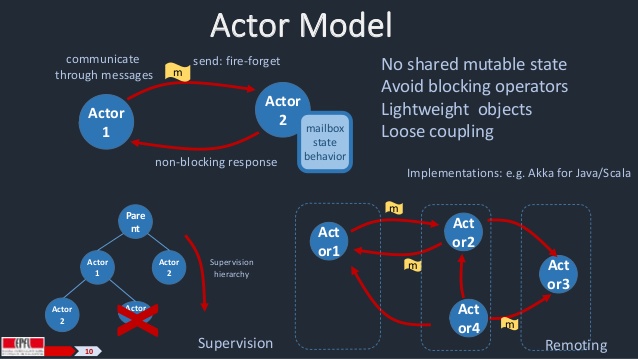
The course covered topics on functional programming principles and implementations of those in the form of courseworks and examples. Such topics include functions and evaluations, tail recursion, higher order functions, currying, evaluation and operators, data and abstraction, class hierarchies and
polymorphism in scala, recursion, types and patterm matching, subtyping and generics, decomposition. It also includes chapters on lists, pairs and tuples, implicit parameters, higher-order list functions, reduction of lists, maps and other collections, combinatorial search and for-expressions. The final chapter was on lazy evaluation and the use of streams for computing infinite sequences. The course included courseworks on sets, Huffman coding, analysis of twitter data, anagrams and streams.
Some statistics on the participants of this course follow. 4596, out of nearly 10000 students that received a certificate for the course, responded to the survey.
The field of study for the majority of the participants seems to be computer science and computer/ software engineering. There were some participants from statistics, maths, electrical engineering and physics.
At least 87% of the students have a university degree. Of these more than half are MScs or PhDs. This demonstrates that Scala attracts the interest of people with high level of academic achievements.
Nearly half of the participants (40%) will use the acquired knowledge at team or individual projects at work.
The following map shows the number of participants per country. 477 people from UK (6.37%) took the course.
2. Machine Learning, Stanford
 In addition to the Functional programming in Scala course, I took the Machine Learning course from Stanford, taught by Andrew Ng, and completed it with distinction.
In addition to the Functional programming in Scala course, I took the Machine Learning course from Stanford, taught by Andrew Ng, and completed it with distinction.
The course contained material on linear algebra, univariate and multivariate linear regression, logistic regression, one-vs-all classification, regularisation, neural networks representation and learning, feed forward, back propagation, multi-class classification, machine learning system design, bias-variance, Support Vector Machines (SVMs), unsupervised learning, clustering, dimensionality reduction, k-means, Principal Components Analysis (PCA), anomaly detection, recommender systems and large-scale machine learning.
I used Octave for the programming exercises, which included implementations for spam classifier, image compression, low-dimensional representation of face images, hand written digits recognition, detection of failing servers on a network, collaborative filtering for recommender system for movies.

I would like to implement some of exercises in Scala and try Spark, an open source cluster computing system that aims to make data analytics fast. It provides primitives for in-memory cluster computing, so that you can load data into memory and query it repeatedly much more quickly than with disk-based systems like Hadoop and MapReduce. Spark was initially developed for iterative algorithms, which are common in machine learning, and interactive data mining. In both cases, it can run up to 100x faster than Hadoop MapReduce. It can also be used for general processing too.
3. Algorithms I, Princeton
Furthermore, I completed the Algorithms I course from Princeton, taught by Robert Sedgewick and Kevin Wayne.
The course was on fundamental data types, algorithms and data structures with emphasis on performance of Java implementations. Topics covered include union-find algorithms, basic iterable data types (such as stack, queues and bags), sorting algorithms (insertion sort, selection sort, shellsort, quicksort, 3-way quicksort, mergesort, heapsort, binary heaps) and applications, priority queues, binary search trees, red black trees, separate chaining and linear probing hash tables, Graham scan for computing the convex hull of a finite set of points in the plane with time complexity O(nlogn), kd-trees and symbol-table applications.
The material can be found on the Algorithms, 4th edition by R. Sedgewick and K. Wayne.
There is a part II on this course, which I am planning to follow later on this year.
4. Computing for Data Analysis, John Hopkins University
This course was on R programming and application to statistical data analysis. More specifically, it covers the flow of retrieving, organising and summarising the data. In addition it includes plotting data for exploratory purposes, exploratory statistical models, statistical models for inference (linear models, basic confidence intervals/ hypothesis testing), cross-validation, exploratory and expository graphs, hierarchical clustering, k-means clustering, dimensionality reduction and Singular Value Decomposition (SVD).
This course has helped me get closer to the data and understand better the difficulties of gathering and cleaning a dataset. It also helped me learn how to create useful graphs for visualising my dataset.
In the future...
Those were some interesting courses and there are even more exciting courses to follow. It feels like I am doing a part time MSc, while having a full time job.




















{kind=link}